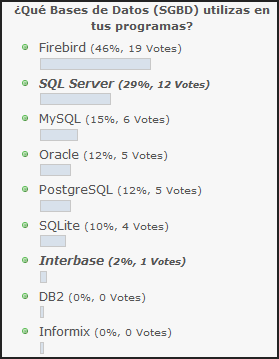
Hoy se ha cerrado la encuesta que había en el Blog referente al SGBD que la gente usa en sus programas.
Me ha servido un poco, para probar el plugin de encuestas, pero también (aunque los votantes no han sido muchos en esta «prueba piloto») me ha sorprendido un poco el resultado.
Sinceramente no pensé que SQL Server apareciera tan arriba. Personalmente trabajo con ella y me gusta mucho, pero la gente suele ser reacia en los foros a utilizarla (o eso me parecía a mi desprender de los comentarios que leía).
También creo que es una solución más a nivel profesional, mientras que me da la impresión que Firebird, puede ser más una elección personal. Eso explicaría que la gente la use, aunque no les acabe de gustar (por obligación) ;-D
Embarcadero MVP.
Analista y Programador de Sistemas Informáticos.
Estudios de Informática (Ingeniería Técnica Superior) en la UPC (Universidad Politécnica de Barcelona).
Llevo utilizando Delphi desde su versión 3. Especialista en diseño de componentes, Bases de Datos, Frameworks de Persistencia, Integración Continua, Desarrollo móvil,…
Continuando con esta entrada (parte 1), nos queda ver como hacer algo similar, pero con un archivo de texto cuyos datos están separador utilizando algun caracter especial (TAB, coma, punto y coma,…)
Por defecto, para la lectura de un fichero de texto medianto ADO (Jet 4.0) se utiliza la información que hay en el registro de windows, que se considera la configuración por defecto. Esta configuración se encuentra en la clave: ‘\SOFTWARE\Microsoft\Jet\4.0\Engines\Text’
Dentro de HKEY_LOCAL_MACHINE y en el valor Format.
De todas formas, para tener un mayor control sobre el procesos para acceder a los datos del fichero de texto, es recomentable (altamente recomendable diría yo) crear un fichero de esquema.
El fichero de esquema siempre tienen el nombre schema.ini y se encuentra en la misma carperta del origen de datos. En el fichero de esquema se definen:
El formato del archivo.
El nombre, la longitud y el tipo de cada campo (columnas).
El juego de caractreres utilizado en el archivo de datos.
Conversiones especiales para los tipos de datos.
Si tuviéramos un archivo similar a este (aunque aquí he utilizado para el ejemplo el separador ‘–‘ que no parace muy adecuado):
El ejemplo completo para acceder a los datos de un TXT utilizando las opciones del Registro de Windows, se pueden descargar desde aquí.
<Descargar ejemplo>
El ejemplo completo para acceder a los datos de un TXT utilizando las opciones de un archivo de esquema schema.ini, se pueden descargar desde aquí.
<Descargar ejemplo>
Embarcadero MVP.
Analista y Programador de Sistemas Informáticos.
Estudios de Informática (Ingeniería Técnica Superior) en la UPC (Universidad Politécnica de Barcelona).
Llevo utilizando Delphi desde su versión 3. Especialista en diseño de componentes, Bases de Datos, Frameworks de Persistencia, Integración Continua, Desarrollo móvil,…
Una de las muchas posibilidades que ADO provee para acceder a diferentes tipos de datos es la que podemos utilizar para acceder a datos de un fichero de Texto, siempre que estos estén mínimamente organizados.
Básicamente trabajamos con dos tipos de ficheros de texto:
Los que los campos son de ancho fijo y por lo tanto no hace falta separador.
Aquellos en los que los datos utilizan un separador de campos. Ya sea «punto y coma», «coma» o cualquier otro.
Configuramos el proveedor como Jet 4.0, en este caso en directorio de la Base de Datois está definido como .\ (el mismo de la aplicación) y en las propiedades extendidas es donde realmente se define el tipo de archivo y la organización de los datos (Text y Fixed).
Sólo nos queda definir en el mismo directorio el fichero schema.ini donde detallaremos la estructura de las columnas de nuestro fichero. Éste sería un fichero correcto para este caso:
De esta forma podemos acceder a los datos del fichero mediante un TADOTable y trabajar con ellos utilizando todas las posibilidades que nos brinde este componente.
El ejemplo completo con el código fuente, el fichero de datos y el fichero de esquema se puede descargar desde aquí.
Embarcadero MVP.
Analista y Programador de Sistemas Informáticos.
Estudios de Informática (Ingeniería Técnica Superior) en la UPC (Universidad Politécnica de Barcelona).
Llevo utilizando Delphi desde su versión 3. Especialista en diseño de componentes, Bases de Datos, Frameworks de Persistencia, Integración Continua, Desarrollo móvil,…
Usamos cookies para asegurar que te damos la mejor experiencia en nuestra web. Si continúas usando este sitio, asumiremos que estás de acuerdo con ello.Aceptar