Utilizar ADO con Threads

 Los threads (o hilos de ejecución), en general, se ven como un tema peliaudo; Son unas «cosas» que están ahí, son buenas (eso dice todo el mundo), pero cuando más se tarde en tener que tacarlos, mejor… ;-D
Los threads (o hilos de ejecución), en general, se ven como un tema peliaudo; Son unas «cosas» que están ahí, son buenas (eso dice todo el mundo), pero cuando más se tarde en tener que tacarlos, mejor… ;-D
Recuerdo que cuando empecé en esto de la programación, los threads o la «programación con múltiples hilos de ejecución» sonaba algo así como «muy difícil». A medida que va pasando el tiempo, uno se da cuenta que que no es así, y cuando has hecho unos cuantos ejemplos te das cuenta de la potencia que aportan y de que realmente sólo hay que tener algunas «precauciones» a la hora de utilizarlos.
En este misma página podéis encontrar algunos ejemplos («ping usando threads», Ejemplo visual y Ejemplo visual ampliado) de programación de hilos de ejecución con Delphi. Ejemplos bastantes sencillos y bastante inútiles, porqué no decirlo, exceptuando la utilidad de aprender cómo funcionan y poder ver un código simple de utilización.
La idea de esta entrada es ir un poco más allá. A veces nos encontramos en una aplicación, con determinadas consultas que tardan mucho tiempo y que no es imprescindible esperar a su finalización para poder continuar con la ejecución normal del programa. Las más comunes serías típicas consultas de Listados, estadísticas o determinadas operaciones que podríamos hacer en 2º plano. Esas consultas serían las candidatas ideales para poder lanzarlas en un Thread independiente del hilo principal del programa.
Para los ejemplos voy a utilizar los componentes ADO y accederemos a la Base de Datos dbdemos.mdb que viene con Delphi.
Para trabajar con ADO utilizando threads, o para lanzar consultas dentro de threads, la única condición es que la conexión (TADOConnection) se cree dentro del mismo thread. Utilizaremos para ello una «cadena de conexión» como propiedad del Thread.
La estructura de la clase podría ser algo así:
TADOSQLThread = class(TThread) private FADOQ: TADOQuery; FSQL: string; FTotalTime:string; public constructor Create(CreateSuspended:Boolean; AConnString:String; ASQL:string); destructor Destroy; override; procedure Execute(); override; property SQL:string read FSQL write FSQL; property ADOQ:TADOQuery read FADOQ write FADOQ; property TotalTime:string read FTotalTime; end; |
Para lanzar desde una aplicación una consulta utilizando nuestra clase TADOSQLThread , debería bastar con asignar la conexión, la cadena SQL, lanzar nuestro thread y esperar a que acabe. El código podría ser este:
//crear el Thread; Pasamos los parámetros de conexión y SQL th := TADOSQLThread.Create(True, AConnection, ASQL); // Evento finalizacion; Al finalizar el control me llegará hasta este evento. th.OnTerminate := TerminateThread; // Ejecutarlo (ponerlo en marcha) th.Resume; |
El código operativo del thread es sencillo, se encuentra en el método Execute y lo único que hace es ejecutar la consulta; En el constructor cremos la nueva Query (con una nueva conexión) y asignamos la SQL.
constructor TADOSQLThread.Create(CreateSuspended:Boolean; AConnString:String; ASQL:string); begin // Creamos el thread inicialmente suspendido (para asignarle las props.) inherited Create(CreateSuspended); // No liberar automáticamente Self.FreeOnTerminate := False; //crea el query FADOQ := TAdoquery.Create(nil); FADOQ.ConnectionString := AConnString; FADOQ.SQL.Add(ASQL); Self.FSQL:= ASQL; end; procedure TADOSQLThread.Execute(); begin inherited; // Ejecutar la consulta Self.FADOQ.Open; end; |
Ahora haría falta probar si en la ejecución de una serie de sentencia SQL con y sin threads se aprecian diferencias visibles. Hay que tener en cuenta que el utilizar o no threads también implica otras cosas.
No todo en este escenario son ventajas, hay que tenerlo en cuenta y entender el funcionamiento para sopesar si en cada caso concreto es beneficioso utilizar threads. Hay 2 grandes inconvenientes que a priori se detectan fácilmente cuando se ejecuta y se prueba un ejemplo como el que vamos a realizar.
Gasto de conexiones: En una ejecución normal, las consultas que se lanzan utilizan todas la misma conexión (ADOConnection); Una premisa que hemos marcado para trabajar con threads, es que cada thread debe funcionar con su conexión propia. Esto implica que en un caso estamos utilizando una única conexión y en el otro X conexiones concurrentes. Esto puede ser un problema en segun qué sistemas.
Sobrecarga de tiempo: El segundo problema (derivado en cierta manera del primero) es la sobrecarga de tiempo que la creación y activación de las nuevas conexiones provoca. Crear, activar (sobre todo este) y liberar las conexiones de cada thread es un tiempo añadido que hay que tener en cuenta.
Estos 2 problemas no se puede solucionar (del todo), pero sí mitigar utilizando un «pool de conexiones«; No es un tema para desarrollar ahora (tal vez más adelante), pero la idea explicada de forma sencilla, es que podemos utilizar un número máximo de conexiones (no tantas como threads). De esta forma, se asigna una conexión libre a un thread cuando la necesita, mientras haya conexiones libres; Cuando ya no quedan libres, el thread debe esperar a que una finalice para que le sea asignada. De esta forma podemos fijar el número máximo de conexiones que se utilizan y además optimizar tiempo, ya que esas conexiones se pueden «reaprovechar» de forma que no exista la necesidad de crear/activar/destruir cada una de ellas.
¿Cuando usar threads y cuando no?
La regla sencilla sería: «Cuanto más grandes y pesadas sean las consultas, más a cuenta sale utilizar threads».
Si lanzamos 20 consultas que tardan muy poco tiempo, el retraso en crear/activar las conexiones de cada una de ellas puede hacer que el tiempo de preparación sea mayor que el de la propia consulta; En ese caso estaremos «gastando» mas tiempo en «preparar» que en «consultar. Por el contrario si esas 20 consultas tardan 30 segundos cada una, el tiempo de extra de conectar para cada una de ellas puede pasar desapercibido (cuando mayor sea el tiempo de consulta, más eficiente este sistema).
Resultado de las pruebas
En las pruebas he lanzado una serie de consultas de forma secuencial. Hay que notar que el tiempo total (para consultas grandes) es sensiblemente menos cuando utilizamos threads; Pero no sólo hay que tener en cuenta el tiempo total, sino el intervalo en que tenemos acceso al resultado de cada consulta.
De forma secuencial, si la primera consulta tarda 10, la segunda 5 y la tercera 7; El tiempo total es de 22, pero los tiempos de acceso a los resultados son 10, 15 y 22 segundos respectívamente; En cambio si esto se hiciera con threads, aun suponiendo que el tiempo total fuera el mismo, los tiempo de acceso a los resultados serían 10, 5 y 7 segundos.
Select * from CustomerSelect * from Employee Select * from CountrySelect * from items Select * from Parts Select * from VendorsSELECT employee.* FROM employee ORDER BY Salary, LastName DESC , FirstName DESC , HireDate DESC SELECT employee.* FROM employee ORDER BY Salary DESC SELECT customer.*, orders.*, items.*, parts.*, vendors.*, vendors.State, items.Discount, orders.SaleDate, * FROM vendors INNER JOIN (parts INNER JOIN ((customer INNER JOIN orders ON customer.CustNo = orders.CustNo) INNER JOIN items ON orders.OrderNo = items.OrderNo) ON parts.PartNo = items.PartNo) ON vendors.VendorNo = parts.VendorNo ORDER BY vendors.State, items.Discount DESC , orders.SaleDate
La primera prueba consta de una serie de consultas que tardan muy poco tiempo, con la Base de Datos de Access DBDEMOS.MDB (que se adjunta con Delphi). En este caso se puede ver que los tiempos de las consultas individuales son sensíblemente más bajos sin threads que con threads, debido a que las consultas con threads incluyen el tiempo de conexión. Finalmente aunque los tiempos individuales son mayores (con threads) el tiempo total queda bastante igualado (se compensa la ejecución con threads con la pérdida en las conexiones).
DATOS SIN THREADS.

DATOS CON THREADS

¿Qué pasaría si lanzáramos algunas consultas que tarden más tiempo?
Para el ejemplo he utilizado datos propios conectando a SQL Server, ya que los de la Base de Datos DBDEMOS sólo nos sirven para realizar pequeñas pruebas. Os animo a que cambieis la conexión ADO que viene en el ejemplo y configuréis vuestra propia conexión y vuestras propias consultas para realizar las pruebas.
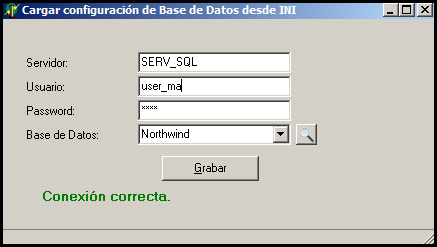
Para la conexión basta con pulsar el botón que aparece en la parte derecha de la conexión:
 Y para las consultas, basta con tener la precaución de colocar el caracter @ al inicio de cada una de las SQL (sólo cuando empieza la consulta, no en el salto de línea).
Y para las consultas, basta con tener la precaución de colocar el caracter @ al inicio de cada una de las SQL (sólo cuando empieza la consulta, no en el salto de línea).

En este caso, vemos que los resultados sí cambian sensiblemente; Lo primero que nos llama la atención, es la diferencia de tiempo total de la serie de consultas (con y sin threads); He realizado unas cuantas ejecuciones, alternando primero unas y luegos las otras y los resultados de tiempos son estos; Los primeros son las consultas normales y los segundos con threads:
Sin threads:
·············································
Tiempo total(todo): 01:19:359
Tiempo total(todo): 01:18:516
Tiempo total(todo): 01:04:500
Tiempo total(todo): 01:08:969
Tiempo total(todo): 01:09:718
·············································
Con threads:
·············································
Tiempo total con threads(todo): 01:00:000
Tiempo total con threads(todo): 00:46:800
Tiempo total con threads(todo): 00:45:484
Tiempo total con threads(todo): 00:53:078
·············································
Posteriormente he lanzado, para variar, 4 ejecuciones concurrentes de ejemplo; 2 con threads y 2 sin threads y el resultado ha sido similar (en cuanto a la diferencia):
·············································
Tiempo total(todo): 01:48:984
Tiempo total(todo): 01:50:860
·············································
·············································
Tiempo total con threads(todo): 01:27:593
Tiempo total con threads(todo): 01:32:860
·············································
CONCLUSIÓN: Aunque el ejemplo es bastante sencillo, y la clase que implementa los threads tiene poca «chicha» yo creo que se ven las posibilidades de utilizar esta opción. También debe quedar claro que no es algo para usar «siempre»; Hemos visto que dependiendo del escenario donde se utiliza puede resultar inútil e incluso contraproducente, ya que gasta más recursos que la técnica sin threads. Como ventaja tenemos que la utilización de threads, en general, nos aporta paralelismo y mayor control en la ejecución del programa (ya que evitamos el «bloqueo» en el caso de una consulta muy costosa).
El código fuente del ejemplo, el binario podeís descargarlo desde aquí.
![]()
Un saludo.
Embarcadero MVP.
Analista y Programador de Sistemas Informáticos.
Estudios de Informática (Ingeniería Técnica Superior) en la UPC (Universidad Politécnica de Barcelona).
Llevo utilizando Delphi desde su versión 3. Especialista en diseño de componentes, Bases de Datos, Frameworks de Persistencia, Integración Continua, Desarrollo móvil,…